



I. Avant-propos▲
Danf est un framework open source de développement d'applications web pour Node.js. Il a été initié par un codeur français et permet de développer de la même manière du côté client et serveur (et même d'utiliser le même code !). Il propose notamment de programmer en orienté objet pour réaliser des architectures complexes grâce à un module d'injection de dépendances inspiré de celui de Symfony2 (le fameux framework PHP), une couche d'abstraction pour gérer facilement et de manière originale des flux asynchrones (fondée sur la bibliothèque async qui permet de gérer des opérations asynchrones complexes) ainsi que plein de petites fonctionnalités comme une gestion simplifiée des cookies, des sessions, et bien plus encore afin d'aider à rentrer simplement dans le monde Node.js particulièrement quand on vient de l'univers PHP. Il permet aussi bien de réaliser des sites web que des API REST (type d'architecture fondée sur le HTTP pour les webservices).
Ce qui le différentie le plus des autres frameworks full-stack est qu'il a un niveau d'abstraction moindre : il n'est pas « magic ». Il rajoute simplement une couche pour exploiter au maximum les forces du Node.js tout en vous laissant libre de vos choix de codage.
Aucune connaissance particulière n'est nécessaire pour mener ce tutoriel à bien, mais une connaissance (même rudimentaire) de Node.js peut aider à en apprécier les subtilités.
Le seul prérequis nécessaire pour réaliser ce tutoriel est d'avoir installé Node.js.
II. Démarrer une nouvelle application avec Danf▲
II-A. Créer un prototype d'application▲
Le meilleur moyen de démarrer une nouvelle application/un module danf (dans Danf une application est un module danf et inversement) est de laisser Yeoman (qui est un générateur de prototypes d'application) le faire pour vous ! Pour cela, ouvrez un terminal et exécutez les instructions suivantes.
Tout d'abord, il faut installer Yeoman :
npm install -g yoEnsuite, il faut installer le générateur d'applications Danf :
npm install -g generator-danfIl ne reste plus qu'à créer l'application (assurez-vous d'être dans le répertoire root de votre nouvelle application) :
yo danfIl est possible d'utiliser n'importe quel module danf comme dépendance d'un autre. Pour cela, il suffit de le rajouter comme dépendance dans le fichier package.json et d'utiliser NPM (le gestionnaire de paquets officiel de Node.js) de la manière la plus standard qui soit. Il est ainsi très simple de rendre des blocs de code réutilisables et partageables.
II-B. Démarrer le serveur▲
Après avoir créé l'application, vous devriez être capable de démarrer le serveur de cette façon :
node app-devUn message de bienvenue vous attend à l'URL http://localhost:3080!
Utilisez app-prod pour démarrer le serveur en environnement de prod (moins de débogage, plus de performances !).
II-C. Exécuter les tests▲
Il est possible d'exécuter les tests de votre application grâce à la commande suivante :
make testIII. Comprendre l'architecture de Danf▲
Dans cette partie, nous allons essayer d'expliquer l'architecture et montrer les possibilités apportées par Danf à travers un exemple simple.
Voici un schéma résumant la macro architecture du framework :
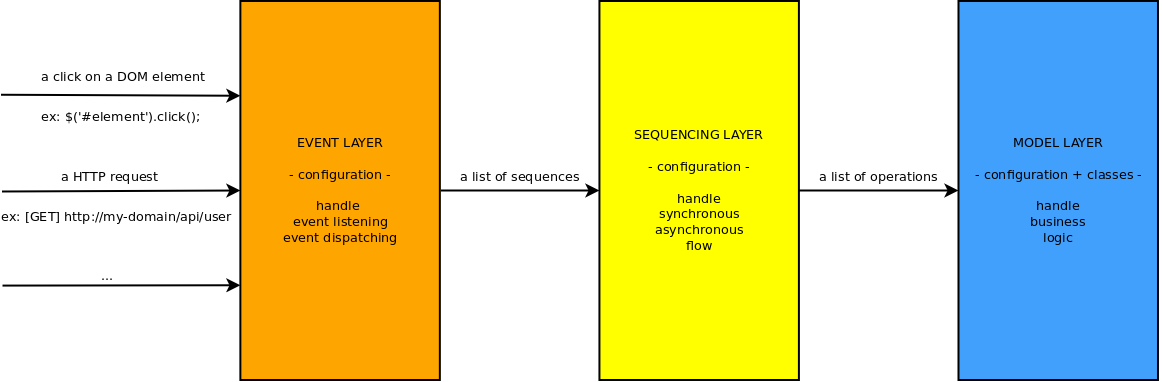
Il y a trois couches principales que nous allons expliciter dans la suite de ce document.
III-A. La couche Model▲
La couche Model est la couche qui contient le code métier et qui permet de définir une architecture orientée objet modulaire et potentiellement complexe.
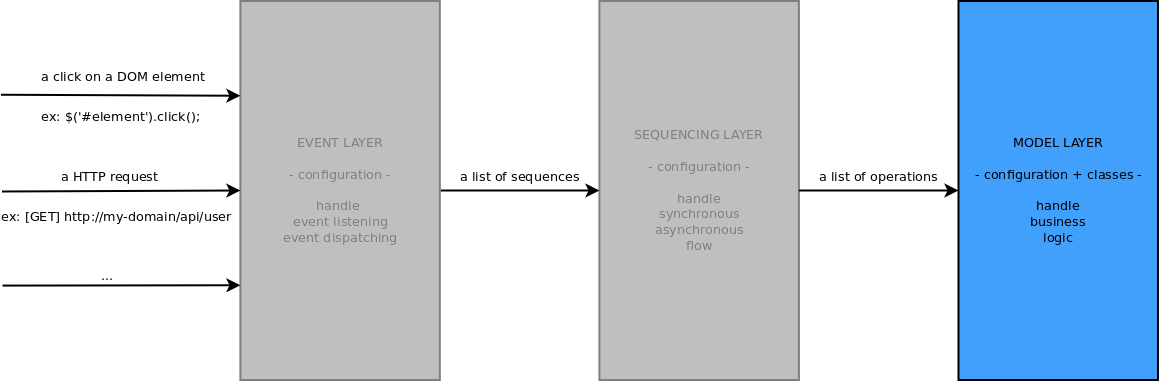
Notre exemple utilise deux classes qui simulent le comportement d'un calculateur et d'un processeur. Le calculateur est capable d'exécuter des calculs synchrones ou asynchrones. Le fonctionnement asynchrone est très important à illustrer, car il est le cœur de la philosophie de Node.js qui traite les entrées/sorties en mode asynchrone afin que le processeur ne passe pas de temps à attendre les retours de base de données ou de lecture de fichiers par exemple. Or, s'il est facile d'exécuter des actions asynchrones en parallèle ou en série (en empilant les callbacks ou mieux les promises) naturellement, il est plus difficile d'en obtenir un code simple et lisible et de manipuler finement une suite d'actions complexes. Nous verrons, au fur et à mesure, la proposition originale faite par Danf pour gérer ce genre de flux.
Les fichiers de classe se situent dans le répertoire /lib. Plus spécifiquement, les fichiers de classe du serveur se trouvent dans /lib/server, ceux du client dans /lib/client et ceux utilisables par les deux dans /lib/common.
// lib/common/computer.js
'use strict';
module.exports = Computer;
function Computer() {
}
// Définit une dépendance que l'injection de dépendances doit remplir.
// Ici, la propriété privée '_processors' doit être un tableau d'objets instances de
// l'interface 'processor'.
Computer.defineDependency('_processors', 'processor_array');
// Définit une propriété.
Object.defineProperty(Computer.prototype, 'processors', {
get: function() { return this._processors; },
set: function(processors) {
this._processors = [];
for (var i in processors) {
var processor = processors[i];
this._processors[processor.order] = processor;
}
}
});
// Définit une méthode.
Computer.prototype.compute = function(value, timeout) {
var self = this;
// Gère un calcul asynchrone.
if (timeout) {
// Enveloppe une opération asynchrone afin de retourner
// le résultat au flux (stream).
this.__asyncProcess(function(returnAsync) {
// Simule un calcul asynchrone.
setTimeout(
function() {
for (var i = 0; i < self._processors.length; i++) {
value = self._processors[i].process(value);
}
// Retourne la valeur calculée au flux.
returnAsync(value);
},
timeout
);
});
// Gère un calcul synchrone.
} else {
for (var i = 0; i < this._processors.length; i++) {
value = this._processors[i].process(value);
}
// Retourne la valeur calculée au flux.
return value;
}
}On peut noter que, la seule différence entre une méthode synchrone et une méthode asynchrone est l'enveloppe this.__asyncProcess(function(returnAsync) { ... } et l'utilisation de returnAsync(value) à la place de return value;.
// lib/common/processor.js
'use strict';
module.exports = Processor;
function Processor() {
}
// Définit les interfaces implémentées par la classe.
Processor.defineImplementedInterfaces(['processor']);
Processor.defineDependency('_order', 'number');
Processor.defineDependency('_operand', 'number');
Processor.defineDependency('_operation', 'function');
Object.defineProperty(Processor.prototype, 'order', {
get: function() { return this._order; },
set: function(order) { this._order = order; }
});
Object.defineProperty(Processor.prototype, 'operand', {
get: function() { return this._operand; },
set: function(operand) { this._operand = operand; }
});
Object.defineProperty(Processor.prototype, 'operation', {
get: function() { return this._operation; },
set: function(operation) { this._operation = operation; }
});
Processor.prototype.process = function(value) {
return this._operation(value, this._operand);
}Voici la définition des services dont vous avez besoin si vous voulez avoir un calculateur qui incrémente une valeur d'entrée de 1 puis qui multiplie ce résultat par 2.
Les fichiers de config fonctionnent de la même manière que ceux de classe (décrits plus haut) sauf qu'ils se situent dans le répertoire /config. Par défaut, pour déclarer un service utilisable par le serveur et le client, il faut le définir dans le fichier /config/common/config/services.js :
// config/common/config/services.js
'use strict';
module.exports = {
// Définit un service.
computer: {
// Définit la classe associée au service.
// Par défaut, le nom d'une classe est un nom logique
// fabriqué à partir de son chemin:
// /lib/server/class.js => class
// /lib/server/foo/bar.js => foo.bar
// /lib/common/class.js => class
// /node_modules/dependency/lib/common/class.js => dependency:class
class: 'computer',
// Définit les propriétés injectées au service.
properties: {
// Injecte les services appartenant à la collection 'processor'.
// dans la propriété 'processors'.
processors: '&processor&'
}
},
processor: {
class: 'processor',
// Lie le service à une ou plusieurs collections.
collections: ['processor'],
// Définit des services enfants héritant de la définition des attributs
// de leur parent abstrait (ici 'class' et 'collections').
children: {
// Définit le premier enfant dont le nom complet est 'processor.inc'.
inc: {
properties: {
order: 0,
operand: 1,
operation: function(value, operand) {
return value + operand;
}
}
},
// Définit un second enfant dont le nom complet est 'processor.mul'.
mul: {
properties: {
order: 1,
operand: 2,
operation: function(value, operand) {
return value * operand;
}
}
}
}
}
};Enfin, voici la définition de l'interface pour les processeurs (permettant de vérifier le respect des signatures des méthodes et donc de définir un contrat d'utilisation et réaliser un faible couplage entre le calculateur et ses processeurs qui sont les bases d'une programmation orientée objet de qualité industrielle).
Par défaut, le fichier pour définir une interface utilisable côté client et côté serveur est /config/common/config/interfaces.js :
// config/common/config/interfaces.js
'use strict';
module.exports = {
// Définit une interface.
processor: {
// Définit les méthodes de l'interface.
methods: {
// Définit une méthode avec le type de ses arguments et
// de son retour.
process: {
// '/value' est simplement utilisé pour la lisibilité et
// le débogage.
arguments: ['number/value'],
returns: 'number'
}
},
// Définit les getters de l'interface.
getters: {
order: 'number'
}
}
};III-B. La couche Sequencing▲
La couche Sequencing est la couche responsable de la gestion de l'asynchronicité et de l'appel à la couche métier.
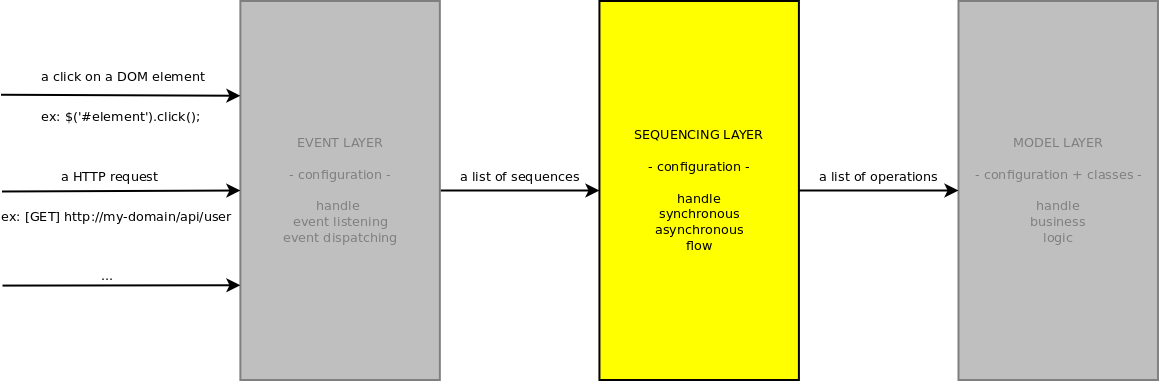
Voici une séquence vraiment simple utilisant le code que nous avons écrit dans la couche Model.
Par défaut, le fichier pour définir une séquence utilisable côté client et côté serveur est /config/common/config/sequences.js :
// config/common/config/sequences.js
'use strict';
module.exports = {
// Définit une séquence.
Define a sequence.
simple: {
// Vérifie le flux d'entrée.
// Ici, le flux d'entrée est un objet contenant une propriété 'value',
// une propriété 'timeout' et une propriété 'name'.
// En l'absence de définition de cet attribut,
// le flux d'entrée est libre.
stream: {
value: {
type: 'number',
required: true
},
timeout: {
type: 'number',
default: 10
},
name: {
type: 'string',
required: true
}
},
// Définit les opérations exécutées par la séquence.
operations: [
// Définit une opération qui est un appel d'une méthode
// d'un service avec des arguments.
// '@value@' et '@timeout@' sont des références résolues
// dans le contexte du flux.
// Le scope est le nom de la propriété du flux qui est impactée
// par le retour (synchrone ou asynchrone) de l'opération.
{
service: 'computer',
method: 'compute',
arguments: ['@value@', '@timeout@'],
scope: 'value'
}
],
// Lie la séquence à une ou plusieurs collections.
collections: ['computation']
}
};Exemples (flux d'entrée => flux de sortie) :
- {name: 'foo', value: 10, timeout: 10} => {name: 'foo', value: 22, timeout: 10} (asynchrone) ;
- {name: 'foo', value: 10, timeout: 0} => {name: 'foo', value: 22, timeout: 0} (synchrone).
La façon de définir une séquence ne diffère pas pour des opérations synchrones ou asynchrones.
Essayons, maintenant, une séquence un peu plus compliquée. Pour cela, on rajoute dans le fichier /config/common/config/sequences.js :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
unpredictable: {
stream: {
value: {
type: 'number',
default: 2
},
name: {
type: 'string',
required: true
}
},
operations: [
{
service: 'computer',
method: 'compute',
arguments: [2, 10],
scope: 'value'
},
{
service: 'computer',
method: 'compute',
arguments: [3, 10],
scope: 'value'
}
],
collections: ['computation']
}
};Dans ce cas, le résultat n'est pas prédictible, car les deux opérations asynchrones sont exécutées en parallèle. La propriété value du flux prendra la valeur de la dernière opération à se terminer (la plupart du temps ce sera le résultat de la seconde, mais pas forcément tout le temps). Ce n'est évidemment pas ce que l'on désirait faire.
Premier cas : on voulait récupérer deux valeurs distinctes :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
parallel: {
stream: {
value1: {
type: 'number',
default: 2
},
value2: {
type: 'number',
default: 3
},
name: {
type: 'string',
required: true
}
},
operations: [
// Utilise 2 scopes différents.
{
service: 'computer',
method: 'compute',
arguments: ['@value1@', 10],
scope: 'value1'
},
{
service: 'computer',
method: 'compute',
arguments: ['@value2@', 10],
scope: 'value2'
}
],
collections: ['computation']
}
};Exemples (flux d'entrée => flux de sortie) :
- {name: 'foo', value1: 2, value2: 3} => {name: 'foo', value1: 6, value2: 8}.
Second cas : on voulait faire le premier calcul, puis utiliser le résultat en entrée du second :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
series: {
stream: {
value: {
type: 'number',
default: 2
},
name: {
type: 'string',
required: true
}
},
operations: [
// Définit un ordre d'exécution.
// Les opérations du même ordre s'exécutent en parallèle.
// Les opérations d'ordres différents s'exécutent en série.
// Par défault, l'ordre est défini à 0.
{
order: 0,
service: 'computer',
method: 'compute',
arguments: ['@value@', 10],
scope: 'value'
},
{
order: 1,
service: 'computer',
method: 'compute',
arguments: ['@value@', 10],
scope: 'value'
}
],
collections: ['computation']
}
};Exemples (flux d'entrée => flux de sortie) :
- {name: 'foo', value: 2} => {name: 'foo', value: 14}.
Il est également possible d'exécuter des opérations sur des tableaux ou des objets :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
collection: {
stream: {
value: {
type: 'number_array',
default: [2, 3, 4]
},
name: {
type: 'string',
required: true
}
},
operations: [
{
service: 'computer',
method: 'compute',
// Définit les arguments pour chaque élément.
// '@@.@@' est une référence résolue dans le contexte
// de l'élément.
// En prenant la valeur par défaut de la propriété 'value'
// du flux d'entrée, les éléments de la collection sont
// 2, 3 et 4.
// @@.@@ sera donc résolu en 2, 3 and 4.
arguments: ['@@.@@'],
scope: 'value',
// Définit la collection sur laquelle aura lieu l'exécution
// de l'opération.
collection: {
// Définit les données de la collection d'entrée.
input: '@value@',
// Definit la méthode d'async utilisée.
method: '||'
}
}
],
collections: ['computation']
}
};Exemples (flux d'entrée => flux de sortie) :
- {name: 'bar', value: [2, 3, 4]} => {name: 'bar', value: [6, 8, 10]}.
Il est possible d'utiliser toutes les méthodes collections de la bibliothèque async. « || » est un raccourci désignant la méthode forEachOf qui représente une exécution en parallèle.
Vous pouvez ajouter des opérations à une autre séquence ou à une collection de séquences en utilisant l'attribut parent. Voici, par exemple, une séquence qui permet de logger les calculs de nos autres séquences :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
log: {
operations: [
{
// Définit l'ordre propre à la séquence.
order: 0,
// Utilise le service danf qui permet d'exécuter une fonction
// (à n'utiliser que pour des tests).
service: 'danf:manipulation.callbackExecutor',
method: 'execute',
arguments: [
function(stream) {
var valueStream = {};
for (var key in stream) {
if (0 === key.indexOf('value')) {
valueStream[key] = stream[key];
}
}
return JSON.stringify(valueStream);
},
'@stream@'
],
scope: 'stream'
},
{
order: 1,
// Utiliser le service danf de log pour logger les entrées
// et sorties des calculs.
service: 'danf:logging.logger',
method: 'log',
// Définit la chaîne de caractères à logger.
// Certaines références peuvent se résoudre à l'intérieur
// même d'une chaîne de caractères.
arguments: ['<<@color@>>@name@ @text@: <<bold>>@stream@']
}
],
// Ajoute les opérations de cette séquence aux opérations des séquences
// appartenant à la collection 'computation'.
parents: [
{
// Définit l'ordre relatif à la séquence cible.
order: -10,
// Définit la cible comme étant les séquences
// de la collection 'computation'.
target: '&computation&',
// Définit le flux d'entrée à partir du flux
// de la séquence cible.
input: {
stream: '@.@',
text: 'input',
color: 'magenta',
name: '@name@'
}
},
{
order: 10,
target: '&computation&',
input: {
stream: '@.@',
text: 'output',
color: 'blue',
name: '@name@'
}
}
]
}
};A contrario, vous pouvez utiliser une séquence dans une autre séquence en utilisant l'attribut children. Voici, par exemple, une séquence qui agrège tous les calculs :
// config/common/config/sequences.js
'use strict';
module.exports = {
// ...
compute: {
// Ajoute des opérations à la liste des opérations de cette séquence.
// Ici, la séquence n'a pas d'opérations propres à elle-même.
children: [
{
// Définit l'ordre relatif à cette séquence.
order: 0,
// Definit le nom de la séquence enfant.
name: 'simple',
input: {
value: 2,
name: 'simple'
},
output: {
result: {
simple: '@.@'
}
}
},
{
order: 0,
name: 'unpredictable',
input: {
name: 'unpredictable'
},
output: {
result: {
unpredictable: '@.@'
}
}
},
{
order: 0,
name: 'parallel',
input: {
name: 'parallel'
},
output: {
result: {
parallel: '@.@'
}
}
},
{
order: 0,
name: 'series',
input: {
name: 'series'
},
output: {
result: {
series: '@.@'
}
}
},
{
order: 0,
name: 'collection',
input: {
name: 'collection'
},
output: {
result: {
collection: '@.@'
}
}
}
]
}
};Dans cette dernière séquence, tous les calculs sont exécutés en parallèle, car l'ordre est le même pour tous les enfants.
III-C. La couche Event▲
La couche Event est la couche responsable de la liaison entre les séquences et des événements spécifiques tels qu'une requête HTTP, un clic sur un élément DOM, etc.
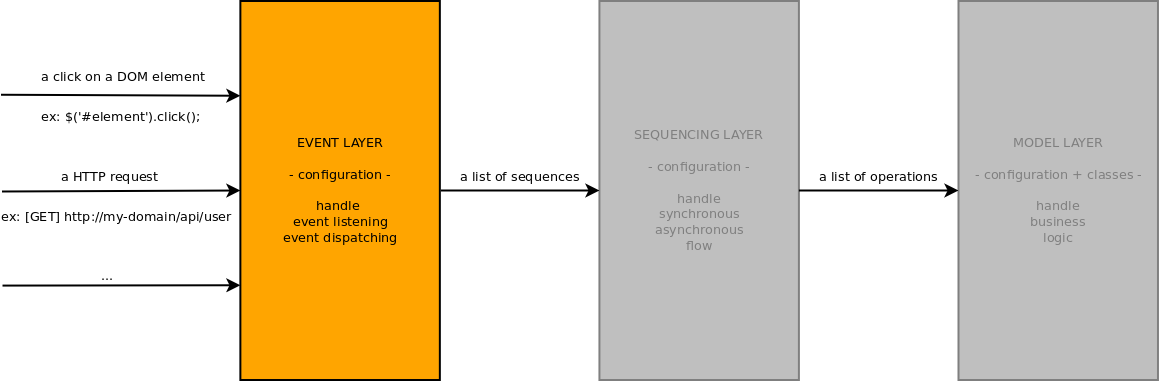
Si vous regardez bien les chemins des fichiers de config précédemment définis, vous vous rendrez compte qu'ils étaient dans le répertoire /config/common. Cela signifie que tous ces codes et définitions seront utilisables aussi bien du côté client (navigateur par exemple) que du côté serveur.
La définition suivante va lier les calculs à une requête HTTP côté serveur.
Par défaut, le fichier pour définir un événement de type requête HTTP est /config/server/config/events/request.js :
// config/server/config/events/request.js
'use strict';
module.exports = {
// Define a request.
home: {
// Définit le chemin de la requête.
path: '/',
// Définit les méthodes HTTP disponibles.
methods: ['get'],
// Lie les séquences.
// Ces définitions fonctionnent de la même manière que les définitions
// des séquences enfants d'une séquence.
sequences: [
{
name: 'compute',
// Set the field "result" of the sequence
// output stream in the field "result"
// of the event stream.
output: {
result: '@result@'
}
}
],
// Définit la ou les vues associées.
view: {
// Définit une vue HTML.
// Il est possible de définir un JSON ou une vue de type texte
// également (ou à la place bien sûr).
// '%view.path%' is a parameter containing the path of
// your current module ('resource/private/view' by default).
html: {
layout: {
file: '%view.path%/layout.jade'
},
body: {
file: '%view.path%/index.jade'
}
}
}
}
};Jade est le moteur de template par défaut, mais il est possible d'utiliser un autre moteur comme décrit dans la documentation d'Express (le framework bas niveau de Node.js sur lequel s'appuie Danf).
Il est possible de changer le fichier index.jade par défaut pour afficher les calculs côté serveur dans le navigateur :
//- resource/private/view/index.jade
h1 Overview
p Here is the output of the server computations:
ul
li= 'Simple: ' + JSON.stringify(result.simple)
li= 'Unpredictable: ' + JSON.stringify(result.unpredictable)
li= 'Parallel: ' + JSON.stringify(result.parallel)
li= 'Series: ' + JSON.stringify(result.series)
li= 'Collection: ' + JSON.stringify(result.collection)
p Take a look at your console to see the client computations!Le flux de l'événement est utilisé comme variable locals pour Jade.
La définition suivante permet de lier les mêmes calculs à l'événement DOM ready de JQuery (la bibliothèque de manipulation du DOM bien connue).
Par défaut, le fichier pour définir un événement de type DOM est /config/client/config/events/dom.js :
// config/client/config/events/dom.js
'use strict';
module.exports = {
// Définit un événement DOM (JQuery).
ready: {
event: 'ready',
sequences: [
{
name: 'compute'
}
]
}
};Maintenant, si vous démarrez le serveur grâce à la commande node app-prod et demandez la page http://localhost:3080/ dans votre navigateur, vous devriez être capable de voir le résultat des calculs dans les consoles à la fois côté serveur et à la fois côté client.
Le fait que toutes les dépendances et les séquences soient définies dans des fichiers de configuration amène de manière naturelle à obtenir des applications dynamiques et évolutives.
IV. Aller plus loin▲
Ce tutoriel qui illustre une vue d'ensemble du framework ne présente pas, bien entendu, les possibilités exhaustives de Danf. Voici un lien vers la documentation (en anglais) si vous souhaitez en apprendre plus.
Maintenant que vous en savez un peu plus sur Danf, pensez-vous qu'il ait sa place parmi l'offre multiple des frameworks Node.js déjà existants ? Pensez-vous qu'il mériterait un test sur l'un de vos projets ?