



VII. Recherche▲
Ce chapitre n'introduit pas de nouveaux concepts spécifiques à JavaScript. À la place, nous allons étudier les solutions de deux problèmes, et discuter de techniques et d'algorithmes intéressants tout au long du chapitre. Si cela ne vous semble pas intéressant, il est possible de sauter ce chapitre.
Laissez-moi introduire notre premier problème. Jetez un coup d'œil à ce plan. Il montre Hiva Oa, une petite île tropicale de l'océan Pacifique.
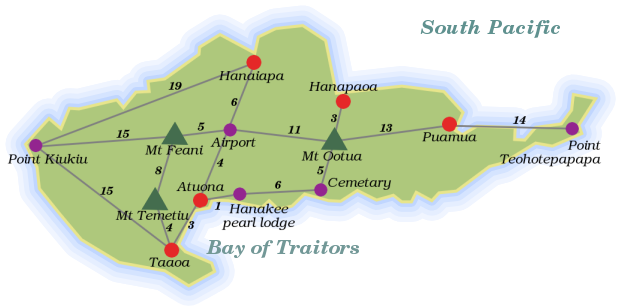
Les lignes grises sont des routes, et les nombres à côté représentent la longueur de ces routes. Imaginez que l'on ait besoin de connaître le chemin le plus court pour relier deux endroits sur Hiva Oa. Quelle approche pourrait-on adopter ?
Non, vraiment, ne lisez pas le paragraphe en diagonale. Essayez de réfléchir sérieusement aux manières de le faire, et réfléchissez aux problèmes que vous pourriez rencontrer. Quand vous lisez un livre technique, il est bien trop facile de parcourir le texte très rapidement, d'acquiescer solennellement et de s'empresser d'oublier ce que l'on a lu. Si vous faites sérieusement un effort pour résoudre un problème, il devient votre problème, et sa solution aura vraiment sens.
Le premier aspect de ce problème est, de nouveau, de représenter nos informations. Les informations contenues dans l'image n'ont pas beaucoup de sens pour l'ordinateur. On pourrait essayer de coder un programme qui étudierait l'image et en extrairait des informations... Mais cela pourrait devenir compliqué. Si on avait vingt mille cartes à interpréter, ce serait une bonne idée. En l'occurrence, on se chargera de faire l'interprétation nous-mêmes, et on convertira les données du plan pour qu'elles soient exploitables en langage informatique.
Que doit savoir notre programme ? Il doit être capable de trouver quels lieux sont connectés, et quelle distance font les routes qui les relient. Les lieux et les routes sur l'île forment un graphe, comme les mathématiciens l'appellent. Il y a plusieurs possibilités pour enregistrer les graphes. Une solution simple consiste à enregistrer dans un tableau des objets de type route, chacun étant doté de propriétés désignant ses deux extrémités et sa longueur.
var routes = [{point1: "Point Kiukiu", point2: "Hanaiapa", length: 19},
{point1: "Point Kiukiu", point2: "Mont Feani", length: 15}
/* et ainsi de suite */];Cependant, il s'avère que lorsque le programme essaiera de déterminer une route, il aura très souvent besoin de consulter une liste de toutes les routes commençant à un point donné, tout comme une personne qui se situe à un carrefour aura besoin de regarder les panneaux de direction et lire « Hanaiapa : 19 km, Mont Feani : 15 km ». Ce serait sympa si c'était facile (et rapide) à faire.
Avec la représentation donnée au-dessus, nous devons éplucher tous les noms de route en gardant ceux qui sont utiles chaque fois que nous voulons ces panneaux de direction. Une meilleure technique serait d'enregistrer cette liste directement. Par exemple, utiliser un objet qui associe les noms de lieux avec la liste des panneaux :
var routes = {"Point Kiukiu": [{to: "Hanaiapa", distance: 19},
{to: "Mont Feani", distance: 15},
{to: "Taaoa", distance: 15}],
"Taaoa": [/* et cetera */]};Quand nous avons cet objet, obtenir les routes qui partent du « Point Kiukiu » revient juste à jeter un œil à routes["Point Kiukiu"].
Toutefois, cette nouvelle représentation contient des données dupliquées : la route reliant A à B est listée à la fois dans A et dans B. La première représentation demandait déjà beaucoup de travail pour rentrer les données, avec celle-là c'est encore pire.
Heureusement, nous avons à notre disposition le talent de notre ordinateur pour la répétition des tâches. On peut indiquer les routes une fois, et faire générer par l'ordinateur la bonne structure de données. D'abord, définissez un objet initial vide appelé routes, et écrivez une fonction ajouterRoute :
var routes = {};
function creerRoute(depart, arrivee, distance) {
function ajouterRoute(depart, arrivee) {
if (!(depart in routes))
routes[depart] = [];
routes[depart].push({arrivee: arrivee, distance: distance});
}
ajouterRoute(depart, arrivee);
ajouterRoute(arrivee, depart);
}Sympa, n'est-ce pas ? Remarquez comment la fonction interne (ajouterRoute) utilise les mêmes noms (depart et arrivee) pour ses paramètres que ceux de la fonction externe. Ils ne vont pas interférer : à l'intérieur de ajouterRoute, ils correspondent aux paramètres de ajouterRoute, et à l'extérieur, ils correspondent aux paramètres de creerRoute.
L'instruction if dans ajouterRoute s'assure qu'il y a un tableau de destinations associées avec le lieu nommé par depart, et s'il n'y en a pas encore, il ajoute une entrée vide. De cette façon, à la ligne suivante il peut supposer que le tableau existe déjà et entrer la nouvelle route dedans.
Maintenant, les informations de la carte ressemblent à ceci :
creerRoute("Point Kiukiu", "Hanaiapa", 19);
creerRoute("Point Kiukiu", "Mont Feani", 15);
creerRoute("Point Kiukiu", "Taaoa", 15);
// ...Dans la description ci-dessus, on a encore trois fois l'occurrence de la chaîne de caractères "Point Kiukiu" à la suite. Nous pourrions générer une description encore plus succincte en permettant à des routes multiples d'être définies sur une seule ligne.
Écrivez une fonction creerRoutes qui accepte un nombre variable d'arguments. Le premier argument est toujours le point de départ des routes, et chaque paire d'arguments qui suit donne le point d'arrivée et une distance.
Ne dupliquez pas la fonctionnalité de creerRoute, mais demandez à creerRoutes d'appeler creerRoute pour réaliser la véritable création de route.
function creerRoutes(depart) {
for (var i = 1; i < arguments.length; i += 2)
creerRoute(depart, arguments[i], arguments[i + 1]);
}Cette fonction utilise un paramètre nommé, depart, et récupère les autres paramètres dans le (presque-) tableau arguments . i démarre à 1 car il doit ignorer le premier paramètre. i += 2 est la simplification de l'équation i = i + 2, comme vous vous rappelez sans doute.
var routes = {};
creerRoutes("Point Kiukiu", "Hanaiapa", 19,
"Mont Feani", 15, "Taaoa", 15);
creerRoutes("Airport", "Hanaiapa", 6, "Mont Feani", 5,
"Atuona", 4, "Mont Ootua", 11);
creerRoutes("Mont Temetiu", "Mont Feani", 8, "Taaoa", 4);
creerRoutes("Atuona", "Taaoa", 3, "Hanakee pearl lodge", 1);
creerRoutes("Cemetery", "Hanakee pearl lodge", 6, "Mont Ootua", 5);
creerRoutes("Hanapaoa", "Mont Ootua", 3);
creerRoutes("Puamua", "Mont Ootua", 13, "Point Teohotepapapa", 14);
show(routes["Airport"]);Nous avons réussi à réduire considérablement notre description des informations sur les routes en définissant quelques opérations pratiques. On pourrait dire que nous avons exprimé l'information de façon plus succincte en élargissant notre vocabulaire. Définir un 'petit langage' comme ceci est une technique très puissante - quand, à tout moment, vous vous retrouvez à écrire du code répétitif et inutile, arrêtez-vous et essayez de réduire ce code avec du vocabulaire qui le raccourcira et le condensera.
Le code redondant est non seulement ennuyeux à écrire mais aussi potentiellement générateur d'erreurs. Les gens font moins attention quand ils font des choses qui ne requièrent pas de la réflexion de leur part. En plus de cela, le code répétitif est dur à modifier, parce qu'une structure, qui répète le même motif un millier de fois, doit également être modifiée un millier de fois si elle s'avère incorrecte ou suboptimale.
Si vous exécutez tous les morceaux de code ci-dessus, vous devriez avoir une variable nommée routes qui contient toutes les routes de l'île. Quand nous avons besoin de la liste des routes qui partent d'un certain lieu, nous pouvons juste faire routes[lieu]. Mais alors, si quelqu'un fait une coquille dans le nom d'un endroit, ce qui est fort probable avec des noms pareils, il récupèrera un undefined à la place du tableau qu'il attendait, et des erreurs étranges peuvent survenir. À la place, nous allons utiliser une fonction qui permet de récupérer les tableaux de routes et qui nous hurle dessus si nous lui donnons un nom de lieu inconnu :
function routesDepuis(lieu) {
var trouve = routes[lieu];
if (trouve == undefined)
throw new Error("Auncun lieu nommé '" + lieu + "' n'a été trouvé.");
else
return trouve;
}
show(routesDepuis("Puamua"));Voici un premier jet pour un algorithme de recherche de chemin, la méthode du joueur :
function routeDuJoueur(depart, arrivee) {
function entierAuHasard(seuil) {
return Math.floor(Math.random() * seuil);
}
function directionAuHasard(depart) {
var options = routesDepuis(depart);
return options[entierAuHasard(options.length)].arrivee;
}
var chemin = [];
while (true) {
chemin.push(depart);
if (depart == arrivee)
break;
depart = directionAuHasard(depart);
}
return chemin;
}
show(routeDuJoueur("Hanaiapa", "Mont Feani"));À chaque branche de la route, le joueur lance son dé pour décider quelle route il va prendre. Si le dé le renvoie à son lieu de départ, ainsi soit-il. Tôt ou tard, il arrivera à destination, du moment que tous les endroits de l'île sont connectés par des routes.
La ligne la plus déroutante est sûrement celle contenant Math.random. Cette fonction renvoie un nombre pseudoaléatoire(12) entre 0 et 1. Essayez de l'appeler un certain nombre de fois à la console, vous verrez qu'il vous donnera (fort probablement) un nombre différent à chaque fois. La fonction randomInteger multiplie ce nombre par l'argument qui lui est donné et arrondit le résultat au chiffre inférieur avec Math.floor. Par exemple, entierAuHasard(3) renverra les chiffres 0, 1 ou 2.
La méthode du joueur est la manière de faire pour ceux qui abhorrent la structuration et la planification, qui cherchent désespérément l'aventure. Nous avons décidé d'écrire un programme qui peut trouver le chemin le plus court pour aller d'un point à un autre, il nous faut donc utiliser une autre méthode.
Une approche très simple est de résoudre un tel problème par la méthode dite « essais et erreurs ». Il faut :
- Générer toutes les routes possibles ;
- Dans cet ensemble, trouver le plus court chemin qui connecte le point de départ au point d'arrivée.
L'étape 2 n'est pas difficile. L'étape 1 est un peu plus problématique. Si vous acceptez des routes avec des boucles, il existe une infinité de routes. Bien sûr, il est peu probable que les routes avec des boucles soient les chemins les plus courts pour aller d'un point à un autre, et les routes qui ne commencent pas au point de départ ne doivent pas non plus être prises en compte. Pour un petit graphe tel que Hiva Oa, il devrait être possible de générer des routes non cycliques (exemptes de boucles) démarrant d'un lieu donné.
Mais d'abord, nous avons besoin de nouveaux outils. Le premier est une fonction nommée member, qui est utilisée pour déterminer si un élément est présent dans un tableau. L'itinéraire (que l'on appellera également route par la suite) sera conservé comme un tableau de noms, et quand le voyageur arrivera à un nouveau lieu, l'algorithme appellera member pour vérifier si le voyageur est déjà passé par cet endroit. Cela peut ressembler à ça :
function member(tableau, valeur) {
var trouve = false;
forEach(tableau, function(element) {
if (element === valeur)
trouve = true;
});
return trouve;
}
print(member([6, 7, "Bordeaux"], 7));Toutefois, ceci va parcourir la totalité du tableau, même si la valeur est trouvée immédiatement en première position. Quel gâchis. Quand vous utilisez une boucle for, vous pouvez en sortir avec l'instruction break, mais dans une structure forEach ceci ne fonctionnera pas, parce que le cœur de la boucle est une fonction et l'instruction break n'interrompt pas une fonction. Une solution pourrait être d'adapter forEach pour qu'il reconnaisse certains types d'exceptions comme un signal pour un arrêt (similaire à break dans les boucles for)
var Break = {toString: function() {return "Break";}};
function forEach(tableau, action) {
try {
for (var i = 0; i < tableau.length; i++)
action(tableau[i]);
}
catch (exception) {
if (exception != Break)
throw exception;
}
}Maintenant, si la fonction action lance un Break, forEach absorbera l'exception et interrompra la boucle. L'objet stocké dans la variable Break est utilisé exclusivement comme un élément de comparaison. La seule raison pour laquelle je lui ai donné une propriété toString est qu'il pourrait être très utile de trouver à quelle étrange valeur vous avez à faire si vous finissez par récupérer une exception Break en-dehors d'un forEach.
Disposer d'un moyen de sortir de boucles forEach peut être très utile, mais dans le cas de la fonction member le résultat demeure assez moche, parce que vous avez besoin de stocker ce résultat particulier et de le retourner plus tard. Nous pourrions encore ajouter une autre sorte d'exception, Return, à laquelle on peut attribuer une propriété value, et faire en sorte que forEach renvoie cette valeur lorsqu'une exception de ce genre est lancée, mais ce serait vraiment spécifique à notre problème et plutôt confus. Ce dont nous avons vraiment besoin c'est d'une nouvelle fonction de haut niveau, appelée any (ou quelquefois some). Elle ressemble à ceci :
function any(test, tableau) {
for (var i = 0; i < tableau.length; i++) {
var trouve = test(tableau[i]);
if (trouve)
return trouve;
}
return false;
}
function member(tableau, valeur) {
return any(partial(op["==="], valeur), tableau);
}
print(member(["Peur", "Répugnance"], "Rejet"));any parcourt tous les éléments d'un tableau, de gauche à droite, et les soumet à une fonction de test. La première fois qu'elle renvoie une valeur comme true, cette valeur est renvoyée. Sinon, elle retourne false. Appeler any(test, tableau) est plus ou moins équivalent à test(tableau[0]) || test(tableau[1]) || ... et cætera.
Tout comme && est le pendant de ||, any a son pendant, appelé every :
function every(test, tableau) {
for (var i = 0; i < tableau.length; i++) {
var trouve = test(tableau[i]);
if (!trouve)
return trouve;
}
return true;
}
show(every(partial(op["!="], 0), [1, 2, -1]));Une autre fonction dont nous aurons besoin est flatten. Cette fonction prend un tableau de tableaux et met les éléments des tableaux dans un unique grand tableau.
function flatten(tableaux) {
var resultat = [];
forEach(tableaux, function (tableau) {
forEach(tableau, function (element){resultat.push(element);});
});
return resultat;
}La même chose pourrait être faite en utilisant la méthode concat et un genre de reduce, mais ceci serait moins efficace. De la même manière, concaténer des chaînes de caractères à de nombreuses reprises est plus lent que les mettre dans un tableau puis appeler la méthode join. Concaténer des tableaux de manière répétée produit beaucoup de tableaux intermédiaires et inutiles.
Ex. 7.2
Avant de commencer à générer des routes, nous avons besoin d'une fonction d'ordre supérieur supplémentaire. Celle-ci est appelée filter. Tout comme map, elle prend une fonction et un tableau en arguments, et produit un nouveau tableau, mais au lieu de placer le résultat de la fonction appelée dans le nouveau tableau, elle produit un tableau avec seulement les valeurs de l'ancien tableau pour lesquelles la fonction donnée retourne true (ou une valeur considérée équivalente a true). Écrivez cette fonction.
function filter(test, tableau) {
var resultat = [];
forEach(tableau, function (element) {
if (test(element))
resultat.push(element);
});
return resultat;
}
show(filter(partial(op[">"], 5), [0, 4, 8, 12]));(Si le résultat de cette utilisation de filter vous surprend, souvenez-vous que l'argument donné à partial est utilisé comme le premier argument de la fonction, de manière à ce qu'il finisse à la gauche de >.)
Imaginez à quoi un algorithme permettant de générer des itinéraires pourrait ressembler - il commence au point de départ et génère un itinéraire pour chaque route qui quitte ce lieu. À la fin de chaque route, il continue à générer des itinéraires supplémentaires. Il ne parcourt pas un simple itinéraire, il se ramifie. À cause de cela, la récursion est une manière normale de modéliser ce phénomène.
function itinerairesPossibles(depart, arrivee) {
function trouverItineraires(itineraire) {
function pasParcouru(route) {
return !member(itineraire.lieux, route.arrivee);
}
function continueItineraire(route) {
return trouverItineraires({lieux: itineraire.lieux.concat([route.arrivee]),
length: itineraire.length + route.distance});
}
var fin = itineraire.lieux[itineraire.lieux.length - 1];
if (fin == arrivee)
return [itineraire];
else
return flatten(map(continueItineraire, filter(pasParcouru,
routesDepuis(fin))));
}
return trouverItineraires({lieux: [depart], length: 0});
}
show(itinerairesPossibles("Point Teohotepapapa", "Point Kiukiu").length);
show(itinerairesPossibles("Hanapaoa", "Mont Ootua"));La fonction renvoie un tableau d'objets itinéraire, chacun contenant un tableau de lieux parcourus par l'itinéraire et une longueur. trouverItineraires continue un itinéraire récursivement, renvoyant un tableau avec toutes les extensions possibles de cette route. Quand la fin de l'itinéraire est le lieu défini comme lieu de fin, il retourne juste l'itinéraire, sachant que continuer l'itinéraire serait absurde. Si c'est un autre lieu, il faut donc continuer. La ligne contenant flatten/map/filter est probablement la plus dure à appréhender. Voilà ce qu'elle dit : « Prends toutes les routes partant de ce lieu, en te débarrassant de celles qui vont à des endroits que nous avons déjà visités. Continue chacune de ces routes, ce qui donnera pour chacune d'entre elles un tableau d'itinéraires finis, puis met toutes ces routes dans un grand tableau renvoyé en résultat ».
Cette ligne fait beaucoup de choses. C'est pourquoi une bonne abstraction de la chose peut aider : elle vous permet de dire des choses compliquées sans taper un écran entier de code.
Ceci ne risque-t-il pas de se répéter indéfiniment, en continuant à s'appeler lui-même (via continueItineraire) ? Non, à un certain moment, toutes les routes iront à des lieux déjà traversés par l'itinéraire, et le résultat de filter sera un tableau vide. Cartographier un tableau vide renvoie un tableau vide, l'écraser renvoie également un tableau vide. Donc appeler trouverItineraires dans une impasse entraîne un tableau vide, qui signifie « il n'y a aucun moyen de continuer cet itinéraire ».
Veuillez noter que les lieux sont ajoutés à des itinéraires en utilisant concat et non push. La méthode concat crée un nouveau tableau, alors que push modifie le tableau existant. Parce que cette fonction risque de faire bifurquer divers itinéraires à partir d'une seule portion de route, il ne faut pas modifier le tableau qui représente l'itinéraire original, parce qu'il doit être utilisé plusieurs fois.
Ex. 7.3
Maintenant que nous avons tous les itinéraires possibles, essayons de trouver le plus court. Écrivez une fonction itineraireLePlusCourt qui, tout comme itinerairesPossibles, prend les noms des lieux de début et de fin en arguments. Elle retournera un simple objet itinéraire, du même type que celui que itinerairesPossibles produit.
function itineraireLePlusCourt(depart, arrivee) {
var itineraireLePlusCourtTrouve = null;
forEach(itinerairesPossibles(depart, arrivee), function(itineraire) {
if (!itineraireLePlusCourtTrouve || itineraireLePlusCourtTrouve.length > itineraire.length)
itineraireLePlusCourtTrouve = itineraire;
});
return itineraireLePlusCourtTrouve;
}Le point épineux dans les algorithmes de « minimisation » ou de « maximisation » est qu'il ne faut pas tout massacrer quand un tableau vide est passé à un tel algorithme. Dans notre cas, on sait qu'il y aura au moins une route entre deux lieux donnés, donc nous pouvons simplement ignorer ce problème. Mais ce raisonnement est un peu léger. Que faire si la route entre Puamua et le Mont Ootua, qui est escarpée et boueuse, est emportée par une pluie torrentielle ? Ce serait dommage que cela engendre une erreur dans notre fonction, donc il faut que la fonction renvoie une valeur null quand aucun itinéraire n'est trouvé.
Voici donc une approche très "programmation fonctionnelle", aussi abstraite que possible :
function minimise(func, tableau) {
var plusPetitScore = null;
var trouve = null;
forEach(tableau, function(element) {
var score = func(element);
if (plusPetitScore == null || score < plusPetitScore) {
plusPetitScore = score;
trouve = element;
}
});
return trouve;
}
function getProperty(nomDePropriete) {
return function(objet) {
return objet[nomDePropriete];
};
}
function itineraireLePlusCourt(depart, arrivee) {
return minimise(getProperty("length"), itinerairesPossibles(depart, arrivee));
}Malheureusement, cette version est trois fois plus longue que l'autre. Dans les programmes où vous voulez minimiser un certain nombre de choses, il peut être intéressant d'écrire un algorithme générique comme celui-ci, que vous pourrez réutiliser. Dans la plupart des cas, la première version suffira.
Notez toutefois la fonction getProperty, elle est souvent utile quand on fait de la programmation fonctionnelle avec des objets.
Voyons à quel trajet aboutit notre algorithme entre la pointe Kiukiu et la pointe Teohotepapapa...
show(itineraireLePlusCourt("Point Kiukiu", "Point Teohotepapapa").lieux);Sur une petite île comme Hiva Oa, ce n'est pas une tâche insurmontable de générer tous les itinéraires possibles. Si vous essayez de faire ça sur une carte raisonnablement détaillée de la Belgique, par exemple, cela va prendre un temps ridiculement long, sans parler d'une quantité de mémoire démentielle. Pourtant, vous avez sans doute déjà vu de tels planificateurs d'itinéraires en ligne. Ils vous indiquent un trajet plus ou moins idéal parmi un énorme labyrinthe de routes possibles en quelques secondes à peine. Comment font-ils ça ?
Si vous êtes attentif, vous avez peut-être remarqué qu'il n'est pas nécessaire de générer tous les itinéraires jusqu'au bout. Si nous comparons les itinéraires pendant que nous les élaborons, nous pouvons cesser le calcul de ces itinéraires et dès que nous avons trouvé un premier itinéraire pour notre destination, nous pouvons cesser l'extension des autres itinéraires plus longs que celui-ci.
Pour essayer, nous utiliserons une grille de 20 sur 20 en guise de carte :

Ce que vous voyez là est une carte en relief d'un terrain montagneux. Les points jaunes représentent les pics, et les zones bleues, les vallées. La zone est divisée en carrés de 100 mètres de côté. Nous disposons d'une fonction altitudeEn, qui peut nous donner l'altitude en mètres, de n'importe quel carré de cette carte, dans laquelle les carrés sont représentés par des objets avec des propriétés x et y.
print(altitudeEn({x: 0, y: 0}));
print(altitudeEn({x: 11, y: 18}));Nous voulons traverser ce territoire à pied, en partant en haut à gauche pour arriver en bas à droite. Une grille peut être assimilée à un graphe. Chaque carré est un nœud connecté aux carrés qui l'entourent.
Nous n'aimons pas gaspiller l'énergie, donc nous préférons prendre le chemin le plus facile. Monter est plus pénible que descendre, et descendre plus pénible que marcher sur un terrain plat(13). Cette fonction calcule le « dénivelé » entre deux carrés adjacents, qui représente l'intensité de la fatigue que vous éprouvez à marcher ou grimper de l'un à l'autre. On considère que monter est deux fois plus pénible que descendre.
function distancePonderee(pointA, pointB) {
var differenceHauteur = altitudeEn(pointB) - altitudeEn(pointA);
var facteurElevation = (differenceHauteur < 0 ? 1 : 2);
var distanceaPlat = (pointA.x == pointB.x || pointA.y == pointB.y ? 100 : 141);
return distanceaPlat + facteurElevation * Math.abs(differenceHauteur);
}Notez le calcul de distanceaPlat. Si les deux points sont sur la même ligne ou colonne, ils sont contigus, et la distance qui les sépare est cent mètres. Sinon, on considère qu'ils sont adjacents en diagonale, et la distance en diagonale entre deux carrés de cette taille est cent fois la racine carrée de deux, ce qui fait à peu près 141. Cette fonction n'est pas autorisée à être appelée pour des carrés qui sont éloignés de plus d'une unité (elle pourrait faire une double vérification ... mais elle est trop paresseuse).
Les points sur la carte sont représentés par des objets contenant des propriétés x et y. Ces trois fonctions sont utiles quand on travaille sur de tels objets :
function point(x, y) {
return {x: x, y: y};
}
function ajouterPoints(a, b) {
return point(a.x + b.x, a.y + b.y);
}
function pointsIdentiques(a, b) {
return a.x == b.x && a.y == b.y;
}
show(pointsIdentiques(ajouterPoints(point(10, 10), point(4, -2)),
point(14, 8)));Ex. 7.4
Si nous nous mettons à chercher des trajets sur cette carte, nous aurons encore besoin de créer des « panneaux », des listes de directions que l'on peut prendre à un point donné. Écrivez une fonction directionsPossible qui prend un objet point comme argument et renvoie un tableau des points qui l'environnent. Nous pouvons nous déplacer seulement vers des points adjacents, à la fois en ligne droite et en diagonale, si bien que les carrés ont au maximum huit carrés voisins. Prenez garde à ne pas renvoyer des carrés qui se trouveraient en dehors de la carte. Pour autant qu'on sache, le bord de la carte pourrait bien être le bord du monde.
function directionsPossible(depart) {
var dimensionCarte = 20;
function dansLaCarte(point) {
return point.x >= 0 && point.x < dimensionCarte &&
point.y >= 0 && point.y < dimensionCarte;
}
var directions = [point(-1, 0), point(1, 0), point(0, -1),
point(0, 1), point(-1, -1), point(-1, 1),
point(1, 1), point(1, -1)];
return filter(dansLaCarte, map(partial(ajouterPoints, depart),
directions));
}
show(directionsPossible(point(0, 0)));J'ai créé une variable dimensionCarte, dans le seul but de ne pas avoir à écrire deux fois 20. Si, à un autre moment, nous voulons utiliser la même fonction pour une autre carte, ce serait laborieux avec un code farci de 20, qu'il faudrait tous remplacer un à un. Nous pourrions même aller jusqu'à utiliser dimensionCarte comme argument de directionsPossible, pour pouvoir utiliser la fonction pour différentes cartes sans les modifier. J'ai estimé que ce n'était pas nécessaire dans ce cas, de telles choses peuvent toujours être modifiées quand le besoin s'en fait sentir.
Alors, pourquoi n'ai-je pas ajouté une variable pour stocker 0, qui apparaît également à plusieurs reprises ? J'ai fait comme si les cartes commençaient toujours à 0, donc il est peu probable que cela change, et utiliser une variable pour cela ne fait qu'ajouter du bruit.
Pour trouver une route sur cette carte sans que notre navigateur n'interrompe le programme parce qu'il prend trop de temps à se terminer, nous devons arrêter de faire de l'amateurisme et mettre en œuvre un algorithme sérieux. Beaucoup de travail a été consacré à de tels problèmes dans le passé, et beaucoup de solutions ont été conçues (certaines brillantes, d'autres inutiles). Une solution très populaire et efficace est nommée A* (prononcé A étoile). Nous allons consacrer le reste de ce chapitre à intégrer une fonction de recherche d'itinéraire A* pour notre carte.
Avant que je me penche sur l'algorithme en lui-même, laissez-moi vous en dire un peu plus sur le problème qu'il résout. Le problème avec la recherche de routes par l'intermédiaire de graphes, c'est que dans les grands graphes, il y a énormément de routes. Notre chercheur de route Hiva Oa nous a montré que quand le graphe est petit, tout ce que l'on avait besoin de faire c'était de s'assurer que nos itinéraires ne repassaient pas par des points où ils étaient déjà passés. Sur notre nouvelle carte, ceci ne suffit plus.
Le problème fondamental, c'est qu'il y a trop de possibilités pour aller dans la mauvaise direction. À moins de savoir comment nous diriger vers la destination pendant l'exploration des chemins, un choix que nous faisons pour poursuivre une route donnée va plus probablement nous faire emprunter le mauvais chemin que le bon. Si vous continuez à générer des itinéraires de cette façon, et même si l'un d'entre eux atteint la cible de manière accidentelle, vous ne savez pas si c'est le chemin le plus court.
Donc ce que vous voulez faire, c'est explorer les directions susceptibles de vous amener à la destination finale en premier. Sur une grille comme sur une carte, vous pouvez avoir une petite estimation de l'optimisation d'un tracé en vérifiant sa longueur et la proximité de sa destination avec la cible. En ajoutant la longueur et l'estimation de la distance restante, vous pouvez vous faire une bonne idée des itinéraires qui sont prometteurs. Si vous prolongez les itinéraires prometteurs en premier, vous avez moins de risques de perdre du temps avec ceux qui sont inutiles.
Mais cela ne suffit pas encore. Si notre carte était celle d'un monde parfaitement plat, le chemin qui semble prometteur serait presque toujours le meilleur, et nous pourrions utiliser la méthode ci-dessus pour nous rendre directement au but. Mais nous avons des vallées et des collines sur notre chemin, donc il est difficile de prédire quel itinéraire sera le plus direct. À cause de cela, nous finissons toujours pas explorer beaucoup trop de possibilités différentes.
Pour y remédier, nous pouvons tirer parti du fait que nous recherchons sans arrêt l'itinéraire le plus prometteur. Une fois que l'on a déterminé que le chemin A est le meilleur moyen de se rendre au point X, nous pouvons nous en souvenir. Quand plus tard le chemin B se rend aussi au point X, nous savons que ce n'est pas la meilleure route, donc nous n'avons pas à faire plus de recherches dessus. Ceci peut éviter à notre programme de tracer beaucoup d'itinéraires inutiles.
Donc, l'algorithme ressemble à quelque chose comme ça :
Il y a deux ensembles de données pour garder un historique. Le premier est appelé la liste ouverte, elle contient des itinéraires partiels qui doivent toujours être explorés. Chaque chemin a une note, qui est calculée en additionnant sa longueur à la distance estimée qui sépare du but. Cette estimation doit toujours être optimiste, elle ne doit jamais exagérer la longueur. Le second est un ensemble de nœuds que nous avons parcourus, avec l'itinéraire partiel qui nous y a amené. Celui-ci, nous l'appellerons la liste des nœuds atteints. On commence en ajoutant à la liste ouverte un itinéraire qui contient uniquement le nœud de départ et on l'enregistre dans la liste des nœuds atteints.
Puis, tant qu'il y a des nœuds dans la liste ouverte, nous prenons celui qui a le plus petit score (donc le meilleur), et nous trouvons les directions dans lesquelles il peut continuer (en appelant directionsPossible). Pour chaque nœud obtenu en retour, nous créons un nouveau chemin en le rattachant à notre route initiale et en ajustant la longueur du chemin par l'intermédiaire de distancePonderee. L'extrémité de chacun de ces itinéraires est ensuite recherchée dans la liste des nœuds atteints.
Si le nœud n'est pas dans la liste des nœuds atteints, cela veut dire que nous ne l'avons pas encore rencontré avant, nous ajoutons le nouveau chemin à la liste ouverte, et nous l'enregistrons dans la liste des nœuds parcourus. Si nous l'avons vu avant, nous comparons la note du nouvel itinéraire aux notes des autres itinéraires de la liste des nœuds parcourus. Si le nouveau chemin est plus court, on remplace la route existante avec la nouvelle. Autrement, on se débarrasse du nouvel itinéraire puisqu'on a déjà une manière plus rapide de se rendre à ce point.
On continue ainsi jusqu'à ce que l'itinéraire que nous sortons de la liste des nœuds parcourus atteigne le nœud correspondant au but ultime, auquel cas nous avons trouvé notre itinéraire, ou jusqu'à ce que la liste des nœuds parcourus soit vide, auquel cas nous nous sommes rendu compte qu'il n'y a pas de route. Dans notre cas, la carte ne contient pas d'obstacles insurmontables, donc il y a toujours un chemin.
Comment savons-nous que le premier itinéraire complet que nous obtenons de la liste des nœuds parcourus est le plus direct ? C'est la conséquence du fait que nous nous intéressons seulement à un chemin quand il fait le score le plus bas. Le score d'un itinéraire est sa longueur actuelle additionnée d'une estimation optimiste de sa longueur restante. Cela veut dire que si un itinéraire obtient la note la plus basse dans la liste ouverte, c'est toujours le chemin le plus direct vers sa destination finale, c'est impossible pour un autre itinéraire de trouver plus tard une meilleure route vers ce point, car si elle était meilleure, son score serait plus bas.
Essayez de ne pas vous énerver lorsque les subtilités de ce fonctionnement vous échappent. Quand on réfléchit à des algorithmes tels que ceux-là, avoir vu avant « quelque chose qui y ressemble » aide beaucoup, cela vous donne un point de repère pour comparer les approches. Les programmeurs débutants doivent faire sans de tels points de repère, ce qui peut les amener facilement à s'égarer. Ayez simplement conscience que ce travail est d'un niveau assez avancé, faites une lecture globale du reste du chapitre, et revenez-y plus tard quand vous vous sentirez de taille à relever le défi.
Je suis désolé de vous l'annoncer, mais pour une partie de l'algorithme, je vais encore devoir invoquer la magie. La liste ouverte nécessite de pouvoir disposer d'une grande quantité de routes, et de trouver rapidement celle qui fait le plus petit score. Les enregistrer dans un tableau normal et parcourir ce tableau chaque fois est beaucoup trop lent, je vous donne donc une structure de données appelée tas binaire. Vous les créez avec new, tout comme les objets Date, en leur donnant une fonction qui est utilisée pour « donner un score » aux éléments passés en argument. L'objet résultant possède les méthodes push et pop, tout comme un tableau, mais pop donne toujours l'élément avec le plus petit score, au lieu de donner celui qui a été ajouté (avec la méthode push) en dernier.
function identity(x) {
return x;
}
var tasBinaire = new BinaryHeap(identity);
forEach([2, 4, 5, 1, 6, 3], function(nombre) {
tasBinaire.push(nombre);
});
while (tasBinaire.size() > 0)
show(tasBinaire.pop());L'appendice 2 traite de l'implémentation de la structure de données, ce qui est assez intéressant. Après avoir lu le chapitre 8, vous pourriez vouloir jeter un œil dessus.
Les nécessités de l'optimisation peuvent avoir un autre effet. L'algorithme d'Hiva Oa utilisait des tableaux de destination pour enregistrer les routes, et copiait celles-ci avec la méthode concat quand il allongeait ces routes. Cette fois, nous ne pouvons pas nous permettre de copier des tableaux puisque nous explorerons des tonnes de chemins. À la place, nous allons utiliser une « chaîne » d'objets pour stocker une route. Chaque objet dans la chaîne possède des propriétés, notamment la position sur la carte et la longueur de la route déjà effectuée, mais garde également en mémoire une propriété qui pointe vers l'objet précédent de la chaîne. Ça donne quelque chose comme ça :
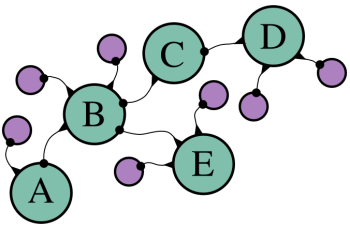
Les cercles couleur cyan sont les objets utiles, et les lignes sont les propriétés. L'objet A est le début de la route ici. L'objet B est utilisé pour construire un nouveau tracé qui se prolonge après A. Quand on doit plus tard reconstruire une route, on peut se reposer sur ces propriétés pour trouver tous les points par où la route est passée. On remarque que l'objet B appartient à deux routes, une qui se termine en D, et une autre qui se termine en E. Quand il y a beaucoup de routes, cela peut nous sauver beaucoup d'espace mémoire, chaque nouvelle route nécessite seulement un nouvel objet pour elle même, le reste est partagé avec les autres routes qui ont commencé de la même manière.
Ex. 7.5
Écrivez une fonction distanceEstimee qui donne une estimation optimiste de la distance séparant deux emplacements. Elle n'a pas besoin de s'intéresser aux données d'altitude, mais peut supposer que le terrain est plat. Rappelez-vous que l'on se déplace seulement tout droit et en diagonale, et que l'on compte les déplacements en diagonale entre deux carrés comme valant 141.
function distanceEstimee(pointA, pointB) {
var dx = Math.abs(pointA.x - pointB.x),
dy = Math.abs(pointA.y - pointB.y);
if (dx > dy)
return (dx - dy) * 100 + dy * 141;
else
return (dy - dx) * 100 + dx * 141;
}Ces formules étranges sont utilisées pour décomposer le trajet en une partie rectiligne et une partie en diagonale. Si vous avec un trajet tel que celui-ci : 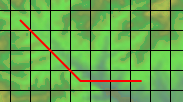
... le chemin fait 8 cases de large et 4 de haut, donc vous avez 8 - 4 = 4 déplacements rectilignes et 4 déplacements en diagonale.
Si vous écriviez une fonction qui calcule la distance « pythagoricienne » directe entre ces points, cela fonctionnerait aussi. Ce dont nous avons besoin est d'une estimation optimiste, et supposer que nous pouvons aller tout droit vers notre but est certainement optimiste. Quoi qu'il en soit, plus notre estimation est correcte, moins notre programme essaiera des itinéraires inutiles.
Ex. 7.6
Nous allons utiliser un tas binaire pour stocker la liste ouverte. Quelle structure serait la bonne pour la liste des nœuds atteints ? Cette liste sera utilisée pour chercher des routes, en lui passant un couple x, y de coordonnées. Rapidement de préférence. Écrivez trois fonctions creerListePointsParcourus, stockerPointsParcourus, et trouverPointsParcourus. La première crée la structure de données ; la seconde, étant donné une liste de nœuds atteints, un point, et une route, stocke cette route ; la dernière, étant donné une liste de nœuds atteints et un point, retourne une route ou undefined pour indiquer qu'aucune route n'a été trouvée pour ce point.
Une idée raisonnable serait d'utiliser un objet avec des objets à l'intérieur. Une des coordonnées des points, par exemple x, est utilisée comme nom de propriété pour l'objet extérieur, et l'autre, y, pour l'objet intérieur. Cela va nécessiter un peu de tenue de compte pour gérer le fait que, parfois, l'objet intérieur que nous recherchons n'existe pas (encore).
function creerListePointsParcourus() {
return {};
}
function stockerPointsParcourus(liste, point, itineraire) {
var listeInterne = liste[point.x];
if (listeInterne == undefined) {
listeInterne = {};
liste[point.x] = listeInterne;
}
listeInterne[point.y] = itineraire;
}
function trouverPointsParcourus(liste, point) {
var listeInterne = liste[point.x];
if (listeInterne == undefined)
return undefined;
else
return listeInterne[point.y];
}Une autre possibilité est de fusionner les x et y du point en un nom unique de propriété, et de l'utiliser pour stocker les itinéraires dans un objet unique.
function pointID(point) {
return point.x + "-" + point.y;
}
function creerListePointsParcourus() {
return {};
}
function stockerPointsParcourus(liste, point, itineraire) {
liste[pointID(point)] = itineraire;
}
function trouverPointsParcourus(liste, point) {
return liste[pointID(point)];
}Définir un type de structure données en fournissant un ensemble de fonctions pour créer et manipuler de telles structures est une technique utile. Cela permet « d'isoler » le code qui utilise la structure, des détails de la structure elle-même. Remarquez que, peu importe laquelle des deux implémentations ci-dessus est utilisée, le code qui a besoin d'une liste des nœuds atteints fonctionne exactement de la même façon. Il ne se préoccupe pas du type d'objet utilisé, tant qu'il reçoit le résultat qu'il attend.
On discutera plus en détail de cela au chapitre 8, où nous apprendrons à faire des types d'objet comme BinaryHeap (tas binaire), qui sont créés en utilisant new et qui ont des méthodes pour les manipuler.
Nous avons donc enfin notre vraie fonction de recherche de chemin :
function trouverItineraire(depart, arrivee) {
var listeOuverte = new BinaryHeap(scoreItineraire);
var pointsParcourus = creerListePointsParcourus();
function scoreItineraire(itineraire) {
if (itineraire.score == undefined)
itineraire.score = distanceEstimee(itineraire.point, arrivee) +
itineraire.longueur;
return itineraire.score;
}
function ajouterItineraireOuvert(itineraire) {
listeOuverte.push(itineraire);
stockerPointsParcourus(pointsParcourus, itineraire.point, itineraire);
}
ajouterItineraireOuvert({point: depart, longueur: 0});
while (listeOuverte.size() > 0) {
var itineraire = listeOuverte.pop();
if (pointsIdentiques(itineraire.point, arrivee))
return itineraire;
forEach(directionsPossible(itineraire.point), function(direction) {
var itineraireConnu = trouverPointsParcourus(pointsParcourus, direction);
var nouvelleLongueur = itineraire.longueur +
distancePonderee(itineraire.point, direction);
if (!itineraireConnu || itineraireConnu.longueur > nouvelleLongueur){
if (itineraireConnu)
listeOuverte.remove(itineraireConnu);
ajouterItineraireOuvert({point: direction,
from: itineraire,
longueur: nouvelleLongueur});
}
});
}
return null;
}Premièrement, il crée les structures de données dont il a besoin : une liste ouverte et une liste des nœuds atteints. scoreItineraire est la fonction de calcul de score passée au tas binaire. Remarquez comment il stocke ses résultats dans l'objet route, pour éviter d'avoir à le recalculer plusieurs fois.
ajouterItineraireOuvert est une fonction commode pour ajouter une nouvelle route à la fois à la liste ouverte et à la liste des nœuds atteints. On l'utilise immédiatement pour ajouter le début de la route. Remarquez que les objets route ont toujours une propriétés point, qui stocke le point d'arrivée de la route, et longueur, qui stocke la longueur courante de la route. Les routes qui ont plus d'une case de longueur, ont aussi une propriété depart, qui pointe sur leurs prédécesseurs.
La boucle while, comme décrit dans l'algorithme, prend constamment la route de plus faible score dans la liste ouverte et vérifie si cela nous mène au but. Si ce n'est pas le cas, on doit continuer en l'étendant. C'est ce dont s'occupe forEach. Il cherche si ce nouveau point est dans la liste des nœuds atteints. S'il ne le trouve pas, ou si le nœud trouvé a une route plus longue que la nouvelle route, un nouvel objet route est créé et ajouté à la liste ouverte et la liste des nœuds atteints, et la route existante (s'il y en a une) est supprimée de la liste ouverte.
Que se passe-t-il si la route dans itineraireConnu n'est pas dans la liste ouverte ? Cela peut arriver, car les routes ne sont supprimées de la liste ouverte que lorsqu'on a déterminé qu'elles étaient la route optimale pour atteindre leur destination. Si nous essayons de supprimer du tas binaire, une valeur qui n'y est pas, cela va lever une exception, donc si mon raisonnement est faux, nous verrons probablement une exception au moment d'exécuter la fonction.
Quand le code devient suffisamment complexe pour vous faire douter de certaines choses à son propos, c'est une bonne idée d'ajouter quelques vérifications qui lèvent une exception quand quelque chose se passe mal. De cette façon, vous savez qu'il ne se passe rien de bizarre « silencieusement », et quand vous cassez quelque chose, vous saurez immédiatement ce que vous avez cassé.
Remarquez que cet algorithme n'utilise pas la récursion, mais réussit quand même à explorer toutes les branches. La liste ouverte remplace plus ou moins le rôle qu'avait la pile d'appels de fonctions dans la solution récursive du problème Hiva Oa : il garde une trace des chemins qui doivent encore être parcourus. Chaque algorithme récursif peut être réécrit d'une façon non récursive et utilisant une structure de données qui stocke les « choses encore à faire ».
Bien, essayons notre recherche de route :
var route = trouverItineraire(point(0, 0), point(19, 19));
Si vous avez exécuté tout le code depuis le début du chapitre, et que vous n'avez pas introduit d'erreurs, cet appel, même si cela peut prendre quelques secondes à s'exécuter, devrait vous donner un objet route. Cet objet est plutôt difficile à lire. On peut le faire en utilisant la fonction showRoute qui, si votre console est assez grande, vous montrera une route sur une carte.
showRoute(route);Vous pouvez également passer plusieurs routes à showRoute, ce qui peut être utile si, par exemple, vous voulez planifier un itinéraire touristique, qui doit inclure le magnifique point de vue en 11, 17.
showRoute(trouverItineraire(point(0, 0), point(11, 17)),
trouverItineraire(point(11, 17), point(19, 19)));Les variations sur le thème chercher un itinéraire optimal dans un graphe peut être appliqué à de nombreux problèmes, dont beaucoup ne sont pas liés au fait de trouver un chemin physique. Par exemple, un programme qui résout le problème de faire rentrer un nombre donné de blocs dans un espace limité peut être résolu en explorant les différents 'chemins' possibles qu'il obtient en essayant de positionner un certain bloc à une certaine place. Les chemins se terminant avec un manque de place pour les derniers blocs sont des culs-de-sac, et le chemin qui permet de faire rentrer tous les blocs dans l'espace est la solution.
